
Wie een temperatuur wil meten, gebruikt een thermometer. Dat lijkt heel simpel en eigenlijk is het dat ook wel. Maar zelfs simpele dingen hebben, als je wat dieper graaft, altijd weer hun complicaties. Zo zou iemand die de temperatuur van de buitenlucht wil meten tot het inzicht kunnen komen dat een thermometer dat helemaal niet kan. Het enige dat een thermometer kan meten is zijn eigen temperatuur.
Nu leert de thermodynamica dat een thermometer die in de buitenlucht hangt vanzelf de temperatuur van de lucht aan zal nemen, op voorwaarde dat er niets anders is dat op één of andere manier energie onttrekt of toevoegt aan die thermometer. In de praktijk betekent dit dat de thermometer niet nat mag worden en niet blootgesteld mag worden aan zonlicht of aan warmtestraling van een bron in de omgeving. In 1864 bedacht Thomas Stevenson een goede afscherming voor thermometers: de Stevensonhut (of Stevenson screen), die de Britse Royal Meteorological Society in 1873 inspireerde tot een lijst van ontwerpcriteria voor thermometerhutten. Instrumentele metingen van voor deze periode worden tegenwoordig met de nodige argwaan bekeken, juist omdat een goede afscherming toen vaak ontbrak. Maar dat betekent niet dat er geen problemen zijn met metingen vanaf 1873. Nog voor het einde van de 19e eeuw werd er een belangrijke tekortkoming in het ontwerp van Stevenson gevonden: via de open bodem van zijn hut kon op zonnige dagen vanaf de grond zonlicht gereflecteerd worden, waardoor metingen te hoog uit konden vallen. Sindsdien zijn er nog allerlei aanpassingen geweest: om de kwaliteit van metingen te verbeteren, om kosten te besparen, om onderhoud te vergemakkelijken, enzovoort.
Voor wie wil weten hoe warm het gisteren was, maken zulke aanpassingen niet veel uit. Voor klimaatwetenschappers, die naar veranderingen in de temperatuur op grotere ruimte- en tijdschalen kijken, is dat anders: als veel thermometerhutten binnen een bepaalde periode op dezelfde manier worden veranderd, kan dat een systematische afwijking van de metingen opleveren. De klimaatwetenschap is hierin overigens niet uniek: vrijwel elke wetenschappelijke discipline die (meet)gegevens over periodes van meerdere decennia gebruikt krijgt met dit soort zaken te maken. Het proces om zulke systematische afwijkingen uit de data te filteren wordt homogenisatie genoemd.

Voorbeeld van een inhomogene reeks temperatuurdata, uit Gemert. De gehomogeniseerde gegevens zijn onderdeel van de Centrale Nederlandse Temperatuur. Meer daarover in dit rapport (pdf) van het KNMI
Natuurlijk zijn in anderhalve eeuw niet alleen thermometerhutten veranderd. Er is veel meer. De thermometer zelf bijvoorbeeld: ooit waren het allemaal kwikthermometers, vaak maximum-minimumthermometers (ik ontdekte tot mijn verbazing dat die al sinds eind 18e eeuw bestaan), terwijl men tegenwoordig vooral elektronische thermometers (of thermokoppels; dit rapport (pdf) van het KNMI uit 1982 beschrijft de invloed daarvan op de metingen) gebruikt. Ook de omgeving van veel thermometers is veranderd. Zo zou in een steeds meer verstedelijkte wereld volgens sommigen het Urban Heat Island effect een rol spelen: het gegeven dat het in een stedelijke omgeving warmer wordt dan op het platteland (de gangbare verklaring is minder afkoeling door verdamping in steden; volgens een recent onderzoek is ook convectie een factor van betekenis). Verstedelijking van de omgeving van een meetpunt zou dus een opwarmend effect kunnen hebben. Dat effect kan eigenlijk geen afwijking worden genoemd, omdat het daadwerkelijk warmer wordt, maar voor onderzoekers die het mondiale klimaat bestuderen vertekent zo’n lokaal effect wel degelijk het beeld en moet het dus uit de data worden gefilterd. Overigens blijken er in de loop der tijd in Europa veel thermometers vanuit steden te zijn verhuisd naar buiten de stad gelegen en dus koelere vliegvelden. Dat ook daarvoor gecorrigeerd moet worden is iets dat de meeste fanatieke pleitbezorgers voor grotere UHI-correcties vaak gemakshalve over het hoofd zien.
Ook het moment waarop thermometers worden afgelezen kan invloed hebben. Om dat te begrijpen, is het belangrijk om te weten dat er niet alleen temperatuurmetingen zijn bij meteorologische instituten of vliegvelden. Op dergelijke plekken worden de temperaturen van oudsher meerdere malen per dag afgelezen en worden tegenwoordig metingen permanent automatisch geregistreerd. Om een goede geografische dekking te krijgen, zijn er ook meetpunten die door vrijwilligers worden beheerd. In zulke meetpunten gebruikt men meestal de al eerder genoemde maximum-minimumthermometers, die één keer per dag worden afgelezen en gereset. Stel nu eens dat dat aflezen en resetten dagelijks om vijf uur in de middag gebeurt. Na het resetten staan de markeringen voor minimum- en maximumtemperatuur op de waarde die op dat moment wordt gemeten. De temperatuur zal in de loop van de avond en nacht vrijwel altijd gaan dalen en de markering voor de minimumtemperatuur doet dat dus ook. Als de temperatuur de volgende dag weer stijgt, zal het regelmatig gebeuren dat die niet het niveau haalt van de markering van het maximum, vastgezet om vijf uur op de vorige dag. In dat geval wordt een te hoge maximumtemperatuur afgelezen. De minimumtemperaturen zijn wel vrijwel altijd juist. Als het aflezen in de ochtend gebeurt, in plaats van de middag, gebeurt precies het omgekeerde. Wat blijkt nu: in de VS werd een grote meerderheid van de metingen in het midden van de vorige eeuw ’s middags afgelezen en tegenwoordig in de ochtend. Een onderzoek uit 2009 van Menne et al. (pdf) bevestigt dat.

Tijdstip waarop thermometers in de VS werden afgelezen. De verschuiving van de middag naar de ochtend in de tweede helft van de vorige eeuw is duidelijk zichtbaar
Homogenisatie begint met het opsporen van inhomogeniteiten in een gegevensreeks. Dat kan op twee manieren. De meest voor de hand liggende is het doorzoeken van logboeken en eventuele andere beschikbare informatie van elke meetlocatie op gegevens over veranderingen: de zogeheten metadata. Het is wel een bijzonder arbeidsintensieve methode en bovendien zullen niet alle veranderingen bij alle meteostations in de wereld goed gedocumenteerd zijn. Daarom zoekt men ook inhomogeniteiten in de data zelf. Bij klimaatgegevens doet men dat meestal door metingen van naburige meetlocaties met elkaar te vergelijken. Er is in de loop der tijd een groot aantal algoritmes ontwikkeld om dergelijke analyses uit te voeren. Veel van die algoritmes kunnen een sprong of afwijkende trend in metingen niet alleen detecteren, maar er ook een kwantitatieve schatting van maken. De kwantificering zal natuurlijk nauwkeuriger zijn als er informatie is over wat er precies wanneer veranderd is bij een meetpunt. Veel meteorologische instituten zullen op de hoogte zijn van in elk geval de belangrijkste wijzigingen in hun stations en die informatie dus mee kunnen nemen. Maar er zijn ongetwijfeld ook datasets waar die informatie ontbreekt. In alle gevallen geldt dat homogenisatie een proces is, dat (systematische) afwijkingen in datasets kan verkleinen, maar onzekerheden nooit helemaal weg kan nemen. De wetenschappers die zich met het onderwerp bezighouden blijven dan ook voortdurend werken aan verbetering.
Onlangs verscheen, voor open review, het artikel met de resultaten van HOME (met als hoofdauteur een bekende van ons blog: Victor Venema), een onderzoek waarin een groot aantal Europese instituten hun algoritmes voor homogenisatie vergeleek en toetste. Het doel van dit project was: orde scheppen in de veelheid van methodes om zo tot een meer gestandaardiseerde aanpak te komen. De werkwijze was in de kern heel simpel: alle algoritmes analyseerden verschillende datasets: homogeen, inhomogeen en voorzien van kunstmatige aangebrachte inhomogeniteiten. Vervolgens werd bekeken hoe goed de algoritmes de aanwezige inhomogeniteiten opspoorden, en of ze “false positives” opleverden. Het artikel laat zien dat het in de praktijk allemaal wat meer voeten in aarde heeft.
De onderzoekers concluderen dat homogenisatie de kwaliteit van datasets verbetert en dat er geen reden is aan te nemen dat het proces kunstmatige trends introduceert. Moderne homogenisatiemethoden blijken aanzienlijk betere resultaten op te leveren dan traditionele methoden. Het project heeft ook twee softwarepakketten opgeleverd voor homogenisatie. Wie zelf eens aan het homogeniseren wil slaan, kan de pakketten downloaden van de site van HOME.
Een vergelijkbaar project is inmiddels, op wereldschaal, gestart door het International Surface Temperature Initiative (ISTI), een organisatie die zich bezighoudt met het opzetten en toegankelijk maken van een databank met alle beschikbare gegevens over de oppervlaktetemperatuur. Voor dit onderzoek is de aftrap gegeven met een artikel, ook al voor open review.
Homogenisatie is een dankbaar onderwerp voor degenen die twijfel willen zaaien over de klimaatwetenschap. Het “aanpassen van data” past niet in het beeld dat veel mensen hebben van “zuivere wetenschap”. De realiteit is natuurlijk dat het kritisch onder de loep nemen van alle data essentieel is in de echte wetenschap, en dat vrijwel alle wetenschappelijke disciplines die gegevens over langere periodes gebruiken op één of andere manier te maken hebben met systematische afwijkingen in hun data, die ze op moeten sporen en corrigeren. De wereld verandert immers, en daarmee de meetmethodes, de omgeving waarin die metingen plaatsvinden en degenen die de metingen uitvoeren. Allemaal factoren om rekening mee te houden.
Een prettige bijkomstigheid voor twijfelzaaiers is het feit dat homogenisatie een aanzienlijk effect heeft op de temperatuurgegevens van de VS, thuisbasis van veel “conservatieve denktanks” en van veel vooraanstaande klimaatwetenschappers. Vooral de eerder genoemde “time of observation” veranderingen hebben veel invloed. De afbeelding hieronder, uit een gastbijdrage van Zeke Hausfather op het blog van Judith Curry, toont het effect van homogenisatie. De afbeelding laat ook zien dat het effect op wereldschaal veel kleiner is en dat de geheel onafhankelijke methoden van Berkely en van NOAA NCDC tot vrijwel identieke resultaten leiden.
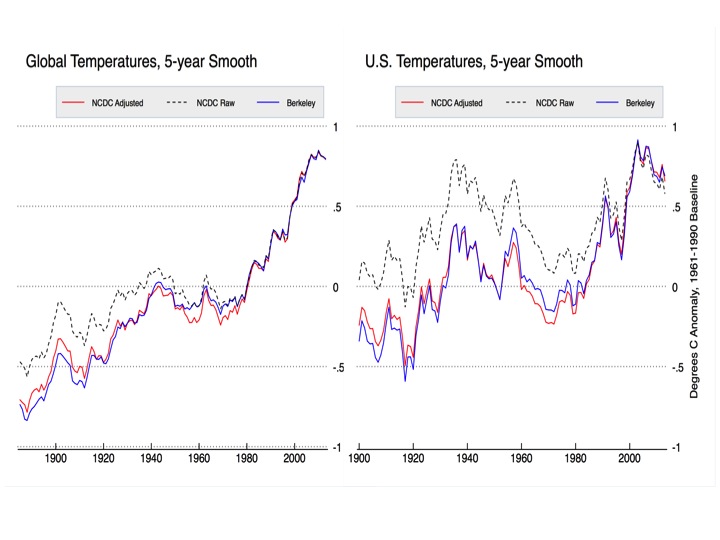
Ruwe en gehomogeniseerde temperatuurdata van de VS en de hele wereld
Een ander bruikbaar gegeven voor twijfelzaaiers is de gewoonte om bij homogenisatie van klimaatgegevens terug in de tijd te werken. De meest recente metingen worden “juist’ verondersteld; als men een inhomogeniteit vindt worden de gevens voor de periode die daaraan vooraf gaat aangepast Het is een keuze die om praktische redenen wordt gemaakt en die men probleemloos kan maken, omdat men alleen naar anomalieën (ofwel veranderingen in de temperatuur) kijkt. Maar het is door twijfelzaaiers makkelijk te “spinnen” als het “steeds weer aanpassen van historische data”.
Het is prima als mensen kritisch naar homogenisatie van klimaatgegevens kijken; de mensen die van dit onderwerp een dagtaak hebben gemaakt doen dat zelf ook. Maar homogenisatie simpelweg afdoen als “geknoei met data” is geen serieuze kritiek; wat mij betreft is dat te kwalificeren als anti-wetenschap. Wie werkelijk meent het beter te weten dan de wetenschap zal veel meer moeite moeten doen.



Hans,
dit thema stond op mijn lijst ‘Snap ik niet goed’ en is er nu afgevoerd! Verder: je exposé is een mooie en kraakheldere illustratie van het concept ‘meten als interface tussen denken en te onderzoeken zaak’ waar de blogpost Via Meten tot Weten etc. over gaat.
LikeLike
Mooi overzicht, Hans.
Een verwijzing die voor dit onderwerp eigenlijk ook niet mag ontbreken is die naar het boek A Vast Machine, van Paul N. Edwards, hoogleraar aan de universiteit van Michigan: http://mitpress.mit.edu/books/vast-machine.
Van de flaptekst:
“Global warming skeptics often fall back on the argument that the scientific case for global warming is all model predictions, nothing but simulation; they warn us that we need to wait for real data, “sound science”. In A Vast Machine Paul Edwards has news for these skeptics: without models, there are no data”.
Ook een schitterend overzicht van hoe de meteorologische en klimaatkennis (en -data/dataverwerking) zich in de loop van de tijd ontwikkelde.
LikeLike
De werkelijkheid van de afgelopen dagen helpt om via een simpel Buienradar-grafiekje nog eens duidelijk te maken dat het moment van aflezen en resetten van een maximum-minimumthermometer invloed kan hebben op de meetresultaten. Hieronder de temperatuur in Rotterdam (gegevens van veel andere plekken zullen hetzelfde beeld geven) van 19 t/m 21 juli.
Zowel op 20 als op 21 juli was de maximumtemperatuur een flink stuk lager dan de temperatuur aan het eind van de middag op de vorige dag. Aflezen en resetten aan het eind van de middag zou dus twee opeenvolgende dagen een te hoge waarde hebben opgeleverd.
LikeLike
@Hans Custers| juli 22, 2014 om 00:34 |:
Om een indruk te krijgen van dit soort effecten is een reeks met uurgegevens nuttig.
Daarmee zijn de afwijkingen van MinMax te bekijken en ook de invloed van de meettijd op de afgelezen temperatuur.
LikeLike
Boels,
Dat spreekt voor zich. Voor zover beschikbaar worden zulke uurgegevens dan natuurlijk ook gebruikt.
LikeLike
De aanpassingen van de temperatuur gaan in die gevallen die ik heb onderzocht, altijd naar beneden, tot soms wel één volle graad aan toe. Zo creëer je als vanzelf een opwarming.
LikeLike
Torsten,
Op niets gebaseerde zware beschuldigingen zijn niet welkom op dit blog. Je openingszin heb ik daarom verwijderd.
Wat je verder beweert is onjuist. Aanpassingen van metingen op land zijn inderdaad vaker naar boven dan naar beneden. Als je de blogpost waar je op reageert had gelezen, had je geweten waarom. Daar staat tegenover dat metingen op de oceanen juist overwegend naar beneden zijn aangepast. De aanpassingen voor land en oceaan samen leveren een trend op die lager is dan die in de ruwe data.
LikeLike
Geachte heer Custers, om gelijk met de deur in huis te vallen behoor ik tot uw categorie twijfelaars of twijfelzaaiers. Ik vind het wel jammer dat u deze indeling nodig vindt. Volgens mij is de wetenschap gebaad bij gas en tegengas, open discussie, uiteraard op overeenkomstig niveau, maar niet bij het polariseren in voor en tegen denkers.
Ik heb met interesse uw stuk gelezen en dank u voor deze verhelderende uitleg over homogenisatie. Er blijven echter wat vraagjes bij mij hangen en misschien kunt/wilt u daar antwoord op geven.
Mijn eerste vraag luidt: is homogenisatie mogelijk zonder parallelle meet data of praten we dan over het bepalen van een gemiddelde?
Is homogenisatie toepasbaar op nieuwe nauwkeuriger metingen tov van oude metingen met onnauwkeuriger apparatuur. Daar bedoel ik mee wanneer ik een meting uitvoer van de buitenlucht met een nauwkeurigheid van +/- 10% en een jaar later voer ik dezelfde meting uit maar dan met een nauwkeuriger meetinstrument (meetnauwkeurigheid 100%) maar natuurlijk in niet volledig identieke weersomstandigheden met al zijn variabelen daarin. Kan ik dan de eerste meting homogeniseren met de tweede meting?
Volgende vraag gaat over het homogeniseren van data van meetstations van het KNMI vanwege verplaatsing en/of plaatsing van nieuwe meet apparatuur. Deze verplaatsingen en/of plaatsing nieuwe meet apparatuur hebben plaatsgevonden in de periode van 1950 tot 1972 bij 5 KNMI weerstations. Er zijn toen parallel metingen uitgevoerd, oude situatie vs nieuwe situatie, en die hebben 5 tot 10 jaar geduurd. In de jaren 1951, 52, 55, 62 en 1970 waren deze parallelle meetresultaten beschikbaar om gebruikt te worden. Dan lijkt het mij volkomen normaal en een logisch uitgangspunt dat op het moment van beschikbaar komen van deze gegevens, deze ook meteen gebruikt zijn om de geconstateerde meetverschillen te verdisconteren. Doe je dat niet dan was het parallel draaien van deze stations niet zinvol of nodig geweest.
Waarom wordt dan pas in 2016, ruim een halve eeuw later, een homogenisatie op basis van deze gegevens uitgevoerd. Of is deze homogenisatie nu twee maal uitgevoerd?
De parallelle metingen zijn allen uitgevoerd door meetstations die dicht bij elkaar lagen. Behalve die van De Bilt. Hier is als parallelle meting de data van Eelde genomen. Eelde ligt op ca 150 km afstand van De Bilt en naar mijn mening te ver om als parallelle meting te kunnen dienen. Dit is duidelijk door het volgende voorbeeldje: Op 23-8-1944 werd er op De Bilt een temperatuur gemeten van 32,8 graden en op 70 km afstand in Warnsveld een temperatuur van 38,6 gradenC. Beide waren geijkte KNMI stations. Is het dan een goede praktijk om de data van De Bilt met behulp van de data Eelde te homogeniseren?
In afwachting van antwoord, met vriendelijke groet Frans van Helvoort.
LikeLike
Frans,
Wat twijfel betreft: ik heb geen enkel probleem met twijfel, of scepsis, binnen de wetenschap. Die is ook in de klimaatwetenschap ruim voldoende aanwezig. En daarom heb ik wel moeite met degenen die twijfel zaaien over de wetenschap. Bijvoorbeeld omdat degenen die dat doen regelmatig geheel ten onrechte suggereren dat klimaatwetenschappers onvoldoende kritisch naar het werk van zichzelf en hun collega’s zouden kijken.
Homogenisatie is niet perfect en dat wordt ook nergens in dit stuk beweerd. En dus is er altijd nog wel iets te verzinnen dat misschien nog wel beter zou kunnen. Ik heb ook nergens in dit stuk beweerd dat het een perfect proces is en dat zullen de wetenschappers die zich ermee bezighouden ook niet beweren. Dat neemt niet weg dat er naar beste weten, met alle kennis die er is, gecorrigeerd wordt voor inhomogeniteiten in data. En dat er alle reden is om aan te nemen dat gehomogeniseerde data een beter (maar dus niet noodzakelijk volmaakt) beeld opleveren van het werkelijke temperatuurverloop dan inhomogene data.
In de wetenschap is sprake van voortschrijdend inzicht. Dat geldt dus ook voor de kennis van en methoden voor homogenisatie. Het is dan ook volkomen logisch dat wetenschappers data uit het verleden zo nu en dan nog eens onder de loep nemen en beoordelen op basis van de nieuwste inzichten. Dat hoort bij het soort scepsis, of twijfel, dat je van serieuze wetenschap mag verwachten. Die scepsis was, zo lijkt me, reden voor het KNMI om in 2016 nog eens naar data uit het verleden te kijken. Het zal mogelijk niet de laatste keer zijn, aangezien de kennis zich altijd blijft ontwikkelen. Wie hecht aan twijfel in de wetenschap, zou dit moeten waarderen.
Tenslotte: dat ergens, op één moment, sprake was van een groot temperatuurverschil tussen Eelde en De Bilt zegt helemaal niets. Dat de temperatuur niet op elk moment identiek is hoeft namelijk helemaal niet te betekenen dat de langetermijntrend niet vergelijkbaar is.
LikeLike
Ik ben het op een aantal punten wel met Frans van Helvoort eens. De homogenisatie van 2014/2016 was op een aantal punten onhandig, en als het nodig was had het beter al eerder kunnen gebeuren. Nu kwam het kort na het verschijnen van de klimaatatlas (2011) die op grote schaal verspreid was, en wat nou juist een standaardwerk had kunnen zijn.
De homogenisatie van de gegevens van De Bilt op basis van de gegevens van Eelde begrijp ik ook niet, en de gebruikte formules ook niet. Het resultaat is vooral van invloed op de maximumtemperaturen. Daardoor zijn veel van de vastgestelde hittegolven vóór 1970 gesneuveld. Misschien terecht, maar voor de communicatie onhandig.
Maar verder moeten we de veranderingen ook niet overdrijven. De gemiddelde temperatuur vóór 1950 is hierdoor met 0,1 à 0,2 graden naar beneden bijgesteld. Dat valt in het niet bij de temperatuurstijging die zich later heeft voorgedaan. De onderstaande figuren zijn gemaakt op basis van een download uit 2010, vóór de homogenisatie.
Klik om toegang te krijgen tot DeBilt_Temp1_original2010.pdf
Klik om toegang te krijgen tot DeBilt_Temp2_original2010.pdf
vergelijk deze met de nu operationele gegevens:
http://logboekweer.nl/Temperatuur/DeBilt_Temp1.pdf (1901 – 1940)
http://logboekweer.nl/Temperatuur/DeBilt_Temp2.pdf (1941 – 1980)
LikeLike
Bart,
Ik wijs er toch maar even op dat dit blogstuk helemaal niet specifiek over de homogenisatie van die gegevens van De Bilt gaat. Het gaat over het hoe en waarom van homogenisatie in het algemeen. Het is een specialistisch onderwerp, dus over de kwaliteit van een specifiek onderzoek matig ik me geen oordeel aan.
Misschien is het communicatief onhandig wat het KNMI heeft gedaan, maar dat heeft dan toch ook veel te maken met de stelselmatige insinuaties die pseudosceptici de wereld insturen over dit onderwerp. Waarin ze bijvoorbeeld stelselmatig niet vermelden dat de mondiale langetermijntrend door homogenisatie naar beneden wordt bijgesteld. Als er reden is om data nog eens kritisch te onderzoeken, en blijkbaar vond het KNMI dat, dan vind ik niet dat men dat moet laten omdat het resultaat misschien kan worden gebruikt in desinformatie-campagnes. Het lijkt me beter als de afweging op louter wetenschappelijke argumenten wordt gemaakt.
LikeLike
@Hans Custers,
Dank voor uw antwoord en als reactie een paar woorden:
Ik heb helaas geen antwoord op mijn eerste vraag gevonden.
Alinea1: Bedoelt u met binnen de wetenschap, de klimaatwetenschappers onderling?
Alinea 2: Ik beweer niet dat uw stuk inhoudelijk niet correct is want ik ben niet deskundig in dat metier. Integendeel uw stuk is voor mij een verduidelijking. Ik ben het ook helemaal met de inhoud van deze alinea eens, onzekerheden blijven altijd bestaan en compenseren voor meetfouten dient altijd te gebeuren.
Alinea 3: Hier begrijp ik uit dat homogenisatie een proces is wat meerdere malen over een zelfde dataset uitgevoerd kan en mag worden. Is dat een correcte handelswijze? Maw. ik begrijp de actie van 2016 niet. De homogenisatie is gedaan aan de hand van parallelle metingen en dan is het proces toch al in de jaren 50-70 uitgevoerd. Mogen er 50 jaar later nieuwe inzichten gekomen zijn kan dat toch niet betekenen dat er wederom een homogenisatie moet worden uitgevoerd. Ten opzichte van wat. De parallelle meting datasets waren al gebruikt. Wat is dan na 50 jaar nog het vergelijkingsmateriaal?
Alinea 4: Er is geen vergelijking gemaakt bij die stations mbv een lange termijn trend. Er is bijstelling verricht op grond van 2 perioden van 3 jaar. En dat is geen lange termijn. Ga je naar de trend kijken ligt eigenlijk alles al vast bij 1 dataset, die van bv de Bilt. Homogenisatie van 2016 was dan overbodig geweest.
In uw reactie naar Bart Vreeken kan ik uw in alinea 1 volgen. Het ging mij over het mechanisme van homogenisatie en heb als voorbeeld de KNMI actie gebruikt omdat uw stuk over homogeniseren van temperatuur data gaat.
Toch proef ik in uw stuk en in uw reactie’s een gevoel van “vijand” denken. Helemaal het laatste deel van uw reactie naar Bart Vreeken. Om iets duidelijk te maken moet dat gebeuren op wetenschappelijke argumenten zoals u meermalen terecht betoogt maar niet op persoonlijke afkeer zoals u hier wel degelijk toont. Jammer.
@ Bart Vreeken,
In uw eerste alinea gaat u er vanuit dat homogenisatie van de parallelle data sets niet uitgevoerd zou zijn. Dat bevreemdt mij ten zeerste. De parallelle metingen zijn weldoordacht en weloverwogen uitgevoerd. Een wetenschappelijk instituut dit laat dit niet 50 jaar op de plank liggen.
In uw figuren komt er idd een subtiel verschil naar voren. Ik heb een lijstje gemaakt adh oude en nieuwe KNMI gegevens en kom helaas tot een verschil van 1,2 tot 1,9 graden C. Helaas is de oude data niet meer beschikbaar bij het KNMI maar nog wel te vinden op het net. Ik vind dat vreemd. Wanneer je transparant opereert had de oude lijst gewoon nog voorhanden moeten zijn met verduidelijking. Juist dit soort acties wakkert alleen maar “onwetenschappelijke” scepsis aan.
Maar nogmaals het ging mij over het mechanisme van homogenisatie en niet om het publiekelijk aankaarten van de handelswijze van de KNMI. Daarvoor moet ik bij het KNMI zijn. Naar aanleiding van uw titel van de publicatie leek het mij niet buitensporig om de homogenisatie van het KNMI hierin te noemen.
met vriendelijke groet Frans
LikeLike
@Frans van Helvoort
– “is homogenisatie mogelijk zonder parallelle meet data of praten we dan over het bepalen van een gemiddelde”
Je zou een blik kunnen werpen op de site van Berkeley Earth. Zij gebruiken een geheel andere methode dan andere onderzoeksgroepen om tot een aaneengesloten temperatuurreeks te komen. Het eindresultaat is overigens zeer vergelijkbaar met de andere onderzoeksgroepen:
http://berkeleyearth.org/faq/#question-14
– “Maw. ik begrijp de actie van 2016 niet. De homogenisatie is gedaan aan de hand van parallelle metingen en dan is het proces toch al in de jaren 50-70 uitgevoerd.”
Als ik de introductie lees in onderstaande pdf, zie ik dat ze daar een hele tijd mee bezig zijn geweest. Er staan bij de introductie verwijzingen naar bijv. Brandsma 2003, Brandsma en Van der Meulen 2007:
Klik om toegang te krijgen tot TR_homogeniseren_dag.pdf
De homogenisatie van 2016 lijkt mij dus het resultaat van een langdurig proces. Maar je zou het hoe en waarom aan het KNMI zelf kunnen vragen, wij zijn hier namelijk niet van het KNMI.
– Helaas is de oude data niet meer beschikbaar bij het KNMI maar nog wel te vinden op het net.
Volgens mij kun je deze data toch gewoon vinden bij het KNMI:
https://www.knmi.nl/nederland-nu/klimatologie/gemeten-reeksen
https://www.knmi.nl/nederland-nu/klimatologie/daggegevens
LikeLike
Frans,
“Bedoelt u met binnen de wetenschap, de klimaatwetenschappers onderling?”
Ja, ik bedoel dat wetenschappers in het algemeen heel kritisch kijken naar hun eigen werk en dat van hun vakgenoten. Overigens is mijn ervaring dat ze vaak ook open staan voor inhoudelijke kritiek van buitenstaanders, als die kritiek tenminste hout snijdt.
“Hier begrijp ik uit dat homogenisatie een proces is wat meerdere malen over een zelfde dataset uitgevoerd kan en mag worden. Is dat een correcte handelswijze? ”
Homogenisatie is het opsporen en zo mogelijk corrigeren van inhomogeniteit in een dataset. Bij mijn weten bestaan er geen dogma’s over wat er wel of niet “mag”. Er is ook geen enkele reden om dat proces te herhalen als daar reden voor is: nieuwe inzichten of betere methodes, bijvoorbeeld. Het lijkt me in het algemeen wel verstandig om dan weer te beginnen met de ruwe data. Die blijven namelijk gewoon beschikbaar.
“Er is geen vergelijking gemaakt bij die stations mbv een lange termijn trend”
Homogenisatie is bedoeld om een zo goed mogelijk beeld te krijgen van de verandering op lange termijn. Om dat te doen worden onder andere stapsgewijze, niet klimaatgerelatieerde veranderingen opgespoord. De correctie is dan ook stapsgewijs, maar dat doet niet af aan het doel: een zo goed mogelijk beeld geven van de trend op lange termijn.
“Toch proef ik in uw stuk en in uw reactie’s een gevoel van “vijand” denken.”
Ik doe niet aan vijanddenken. Dat ik het inhoudelijk niet met iemand eens ben en mogelijk zelfs een stevige repliek schrijf staat los van de persoon. Van een persoonlijke afkeer is dan ook helemaal geen sprake. Volgens mij heb ik ook niemand persoonlijk aangevallen.
“Een wetenschappelijk instituut dit laat dit niet 50 jaar op de plank liggen.”
Daar is nog wel wat over te zeggen. Oorspronkelijk waren weerstations helemaal niet bedoeld om te gebruiken voor klimaatonderzoek. Er was 50 jaar geleden niet of nauwelijks aandacht voor methodes om zo goed mogelijk een lange termijn trend te bepalen. De parallelmetingen zullen destijds zijn uitgevoerd uit pure wetenschappelijke interesse in het verschil tussen verschillende opstellingen. Maar volgens mij bestond het hele concept van homogenisatie nog niet. Daarom is het logisch dat dit niet al 50 jaar geleden is gedaan.
LikeLike
Dank voor uw zeer informatieve antwoorden en linkjes. met vriendelijke groet Frans van Helvoor
LikeLike