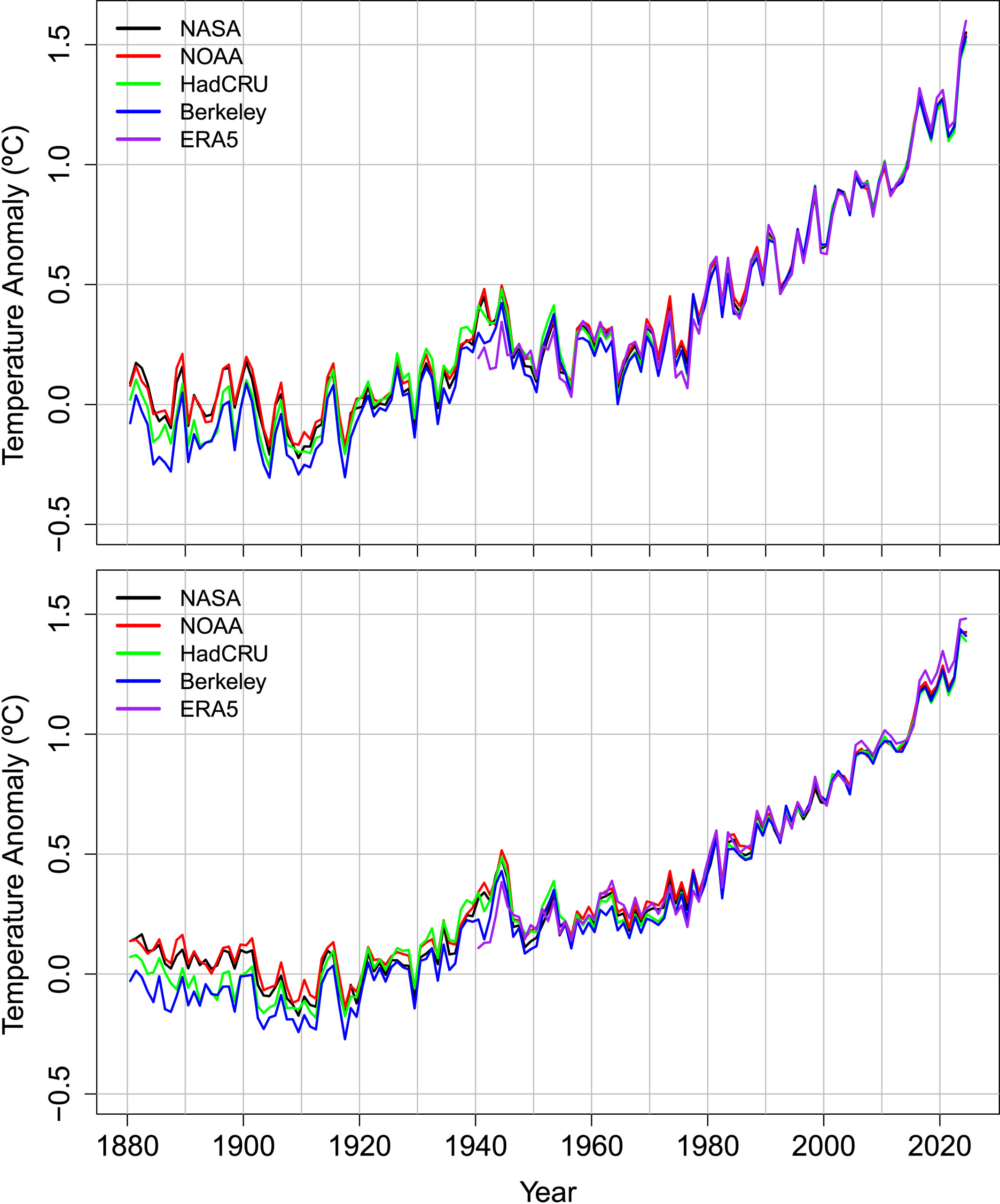
Versnelt de opwarming van de aarde? Die vraag leidt al enkele jaren tot pittige discussies op sociale media, waarin zich regelmatig ook klimaatwetenschappers mengen. Die discussie laaide vorige week weer op, naar aanleiding van een artikel in Geophysical Research Letters. De auteurs zijn vertrouwde namen in het online klimaatdebat. Grant Foster is een statisticus, in klimaatkringen al zo’n twintig jaar bekend als Tamino, van het blog Open Mind. En Stefan Rahmstorf is een door de wol geverfde klimaatwetenschapper van het Potsdam-Institut für Klimafolgenforschung. Hij is een van de bloggers van RealClimate, en was een van de eerste wetenschappers die tien jaar geleden al wees op signalen dat er een vertraging van de circulatie in de Atlantische Oceaan gaande is.
Het onderzoek borduurt voort op een eerdere publicatie van Rahmstorf en Foster uit 2011. Ze presenteerden daar een statistische methode om de belangrijkste oorzaken van variabiliteit van de wereldtemperatuur op korte termijn uit de gegevens te filteren: vulkanische aerosolen, wisselingen in zonne-activiteit en de oscillatie van El Niño’s en La Niña’s (ENSO). Door deze “ruis” grotendeels weg te filteren ontstaat er een beter zicht op het “signaal”: de antropogene opwarming. Een eventuele verandering in de snelheid van opwarming wordt dan beter detecteerbaar. In de afbeelding hieronder is het verschil zichtbaar tussen de gefilterde en de ongefilterde data.